

記者 林鈺庭、黃熙桐、章仁潔、黃茜雯/採訪報導
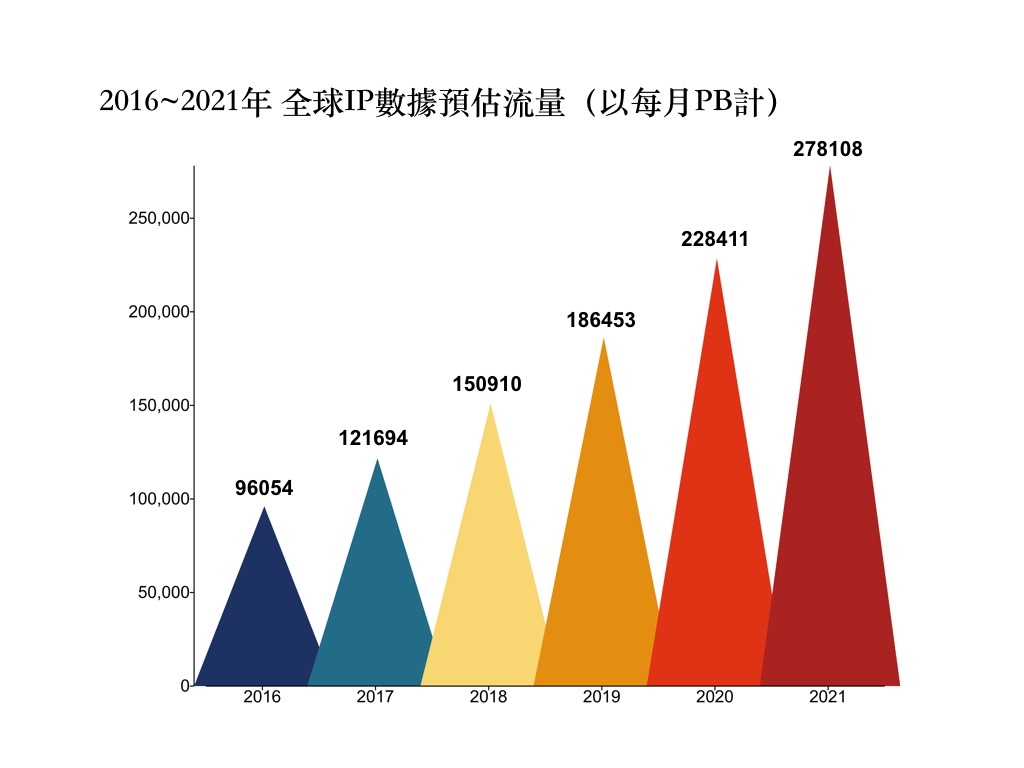
延續前幾期的AI、智慧裝置等科技技術,最大的源頭得歸功於大數據(Big Data),因為它能分析各種資料,而大數據在各個領域被賦予不同的定義和存在,正不知不覺地滲入生活改變著。
解釋大數據 資料多樣性
世新財金系教授何宗武說:「大數據不是因為它有的資料有多龐大,主要還是因為新興的科技的發展,存取的能力及空間都有相對應的技術,能夠處理大量的數據資料,它已經有能力去將兩個不相關的資訊找出連結。」事實上,現階段還沒有辦法儲存處理所有的數據,例如:Google,是全世界第一家把數據當作生產資源的公司,大數據技術其實是所謂的儲存,和串接的技術革新,對此,何宗武也強調,大數據仍有極限,只不過現在的極限早已經超越過去的想像,它可以說是一個索引技術的進步和資料儲存的變革,事實上,沒有一個時代是可以直接去處理數據本體的,每一個時代技術都有限。
很多人會有的疑問是,大數據要多大才稱做是「大」數據?其實在不同研究領域的專家學者都各自有不同的解釋,對此,何宗武說:「首先,研究者本身要有一個問題取向。」相對來說現有的數據研究範疇我們叫它小數據,而大數據就是找到目前龐大資料庫以外的資料,問題本身仍存在於數據上,我們要從其中找出答案,並且去擴大搜索半徑,在解決問題的過程中需要擴充資料的維度(Dimension),再利用點線面的擴張搜索資料,那便能叫做大數據。
同一類的資料再多,其實仍舊是資料,彼此沒有太大的差異,因此不能用資料量去區分大小,如果已經有足夠數據結構找到答案,其實也不必去尋找額外的資料型態,例如:擁有某一筆股票歷史交易紀錄,小至秒,大則年,那還是稱作擁有的資料數據龐大,反觀,擁有一億筆股票歷史交易紀錄,那就是維度的擴增,如此便能稱作大數據。因此回歸到大數據的基本定義層面而言,在不同領域之間的共同特性,仍然是「資料多樣性」。
計算龐大資料量 定義大數據
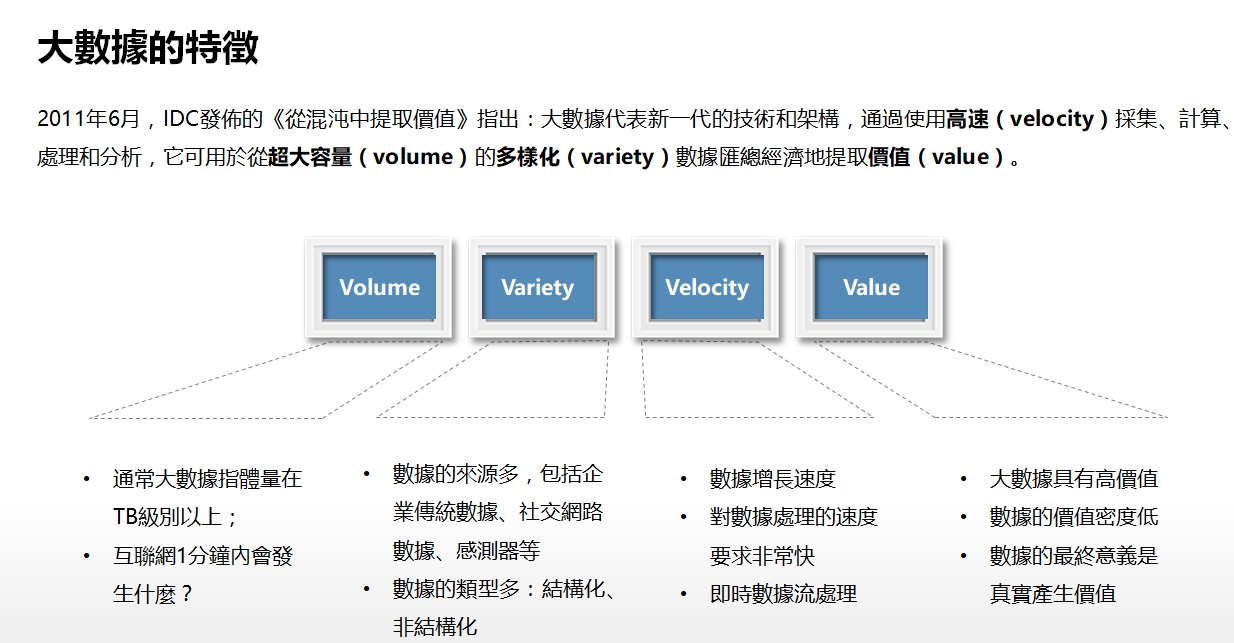
學者對大數據有不同的解釋,世新資管系教授劉育津表示,以資訊的角度來說,大數據的定義除了IBM提出的「5V」特性—Volume(大量)、Velocity(高速)、Variety(多樣)、Value(價值)、Veracity(真實)之外,它的容量必須在PB單位— 10的15次方以上,單看數字可能不明顯,以一般儲存的檔案為例,一個檔案是以KB為單位,也就是10的3次方,手機容量以GB為單位,10的9次方,而大數據卻多於手機容量6個位數,這樣龐大的資料量,需要倚靠足夠強大的硬體設備來分析以及運作,才得以分類檢測。
劉育津表示,因為科技的進步,物聯網發達,人們每天使用的電子設備以及社交軟體,會回傳大量的資訊,相較以前的技術是完全不敢想像的。還記得20年前還在使用磁片日子嗎?當時資料流動的方式就是透過磁片來傳遞,再大的磁片不過是MB為單位,就算一整天傳遞資料,也不可能滿足大數據的基本單位。

這麼大的資料量可以做什麼用途?將資料統整後,可以預先設想問題,再由資料去分析出答案,這便是熟知的統計學,另一方面,在未知問題為何,將資料組合,找出其中的關聯性,這樣的方式稱作「資料探勘」,劉育津認為大數據分析與資料探勘最大的不同是:「大數據包含的多樣性」,一般資料探勘大多分析單一面向,例如:討論物品的數量或購買年齡層,而大數據分析能夠包含與物品有關連性的問題,以多樣面向的角度研究問題。
大數據的定義眾說紛紜,不同專業的學者對大數據有不同的解釋,劉教授認為只要資料量高於PB以及5V的其中一項,就能稱作大數據,但模糊的定義也導致現今學者對大數據這個名詞的濫用,以及濫用大數據分析工具去定義事情,推測的答案不能代表絕對,大數據很方便卻也很危險,因此,善用大數據能帶來便利,也能導致錯誤。
關鍵字蒐集 形成大數據
源大數據科技公司的研究顧問謝長穎表示,在蒐集數據時主要利用兩種方式,網路爬蟲及API(應用程式介面),針對要作分析的主題,利用關鍵字搜尋資料。他又形容這個方式像是在網路上串門一樣,到各個網站敲敲門,把蒐集回來雜亂的資料變成有用的、容易理解的結構化的資料,至於沒有用的資料則清理掉,最後抓取到雲端伺服器。在收集資料前有不少前置作業需要準備,例如:針對主題而設置關鍵字,不過這一點同時亦是把雙面刃,花時間卻能掌握更多針對主題的業務、資訊,而來源方面則固定從Facebook、Youtube、意見領袖的頁面及一些知名新聞傳媒網站等。

以Facebook為例,從粉絲專頁、公開社團中抓取五千到六千筆資料,根據觀察,即過去七天內根據演算法找出如:分享次數越高、留言人數越多,按讚數量等,而每個演算法的演算方法都不一樣。源大的平台實際操作的方式,首先篩選出比較知名的部份,再將數據輸入資料庫,接著需要一定的時間作分析、進行編碼,最後進行實時分析,與傳統的資料蒐集相比,利用網路蒐集資料再輸入後台,大大提升了整體效率跟速度,無論精確性、或是資料的覆蓋範圍,都過之而無不及。
以企業為例 運用大數據在機器人
記憶體大廠威剛科技在上半年時推出了親子陪伴機器人「萌啵啵」,其主要以自然語音互動、幼兒教學陪伴為特色,成功地在各界帶起了一陣討論熱度。而為了提升產品使用質量保證,威剛領先利用「不記名」的雲端數據資料做計算,獲取本月份哪個故事點擊率最高、某應用程式開啟次數最高,掌握整體用戶啟動啟動機器人次數和停留時間,單純以應用程式的開啟數據分析,如此和大數據科技做全方位的結合,完善整體功能,希望能達到整體應用以及產品使用感受的效益最大化。威剛科技公司副理李莉芳也表示「所有未來機器人的終端目標都應該是要以IOT去做發展,讓人能夠有更多時間去專注生活品質。」
面對大數據 帶來的省思
在時代的革新下,我們在數據的洪流中更要具備反思的能力,資料識讀(Data Literacy)也在大數據中扮演重要的角色,而5V中的真實性,也代表分析者能辨識異常資料,當資料的量足夠,同時具有資料識讀的能力的話,或許有可能打破目前因為各種資料不足與資料誤讀所造成的偏見與衝突。如同《經濟學人》所指出:「數據已經是所有成長與改變的驅動力。」

